Selected Publications
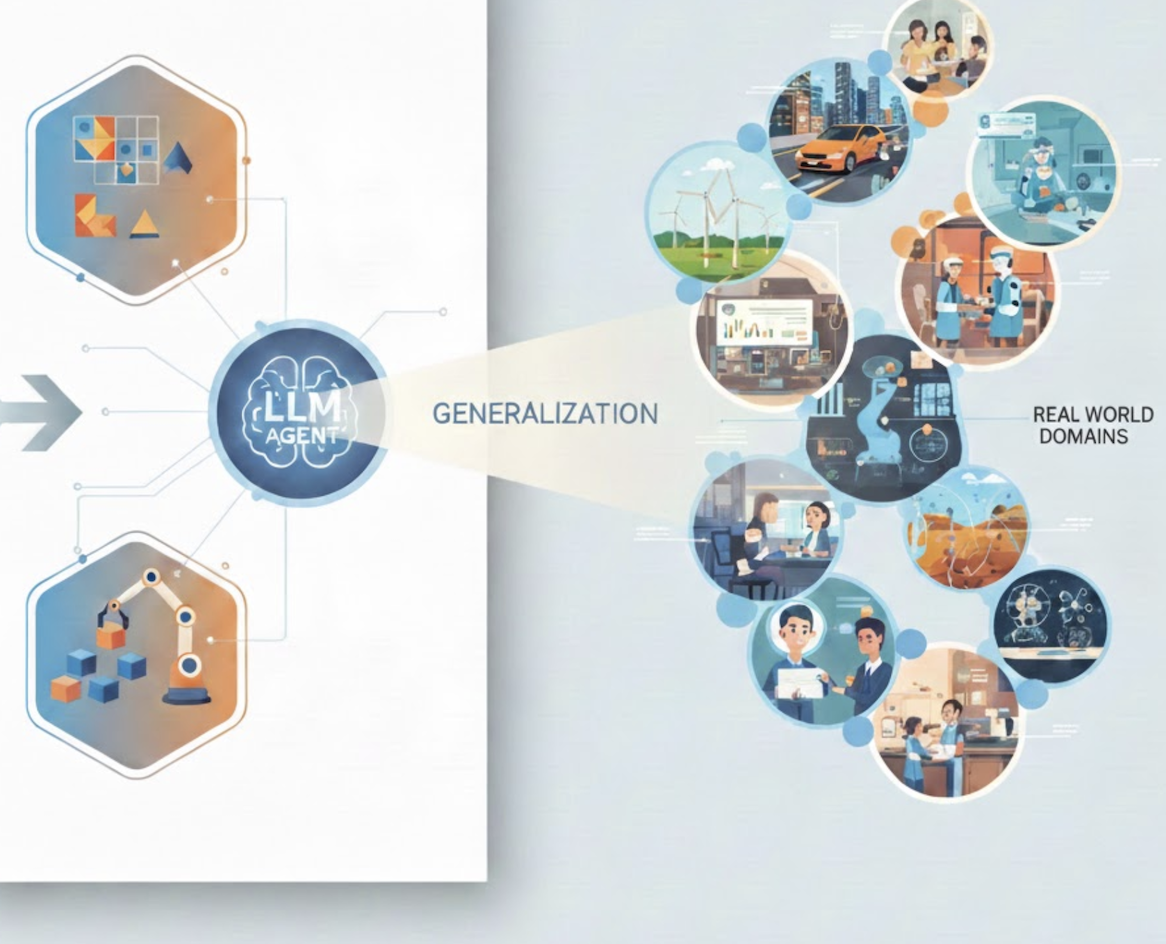 |
Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Zhihan Liu*, Lin Guan* (equal contribution), Yixin Nie, Kai Zhang, Zhuoqun Hao, Lin Chen, Asli Celikyilmaz, Zhaoran Wang, Na Zhang
Preprint
Our study reveals that training environments with higher state information richness and planning complexity are more effective for reducing the 'generalization tax' — a bottleneck of LLM agents when moving from limited training environments to broader, unseen real-world domains. This research also examines how mid-training and explicit thinking reshape knowledge retention and forgetting of RL.
paper
|
 |
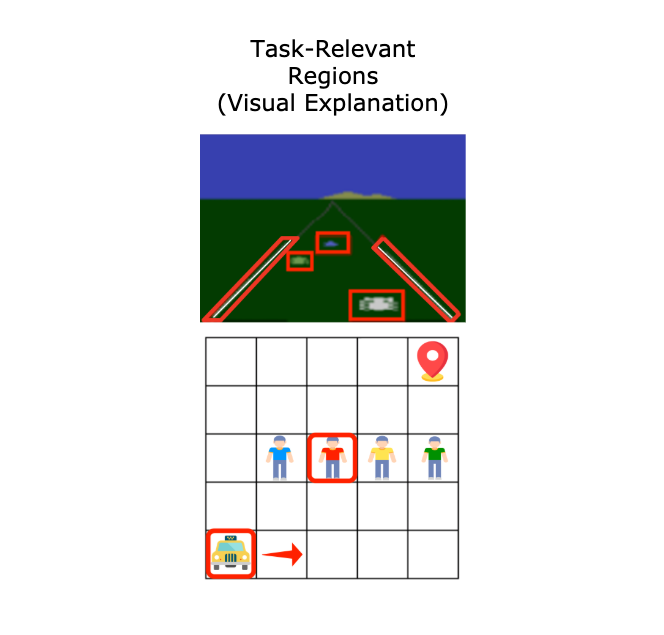
Task Success is not Enough: Investigating the Use of Video-Language Models as Behavior Critics for Catching Undesirable Agent Behaviors
Lin Guan*, Yifan Zhou*, Denis Liu, Yantian Zha, Heni Ben Amor, Subbarao Kambhampati
Conference on Language Modeling (COLM) 2024
When no sound verifier is available, can we use large vision and language models (VLMs), which are approximately omniscient, as scalable Behavior Critics to catch undesirable embodied agent behaviors in videos? To answer this, we first construct a benchmark that contains diverse cases of goal-reaching yet undesirable agent policies. Then, we comprehensively evaluate VLM critics to gain a deeper understanding of their strengths and failure modes.
paper
website
|
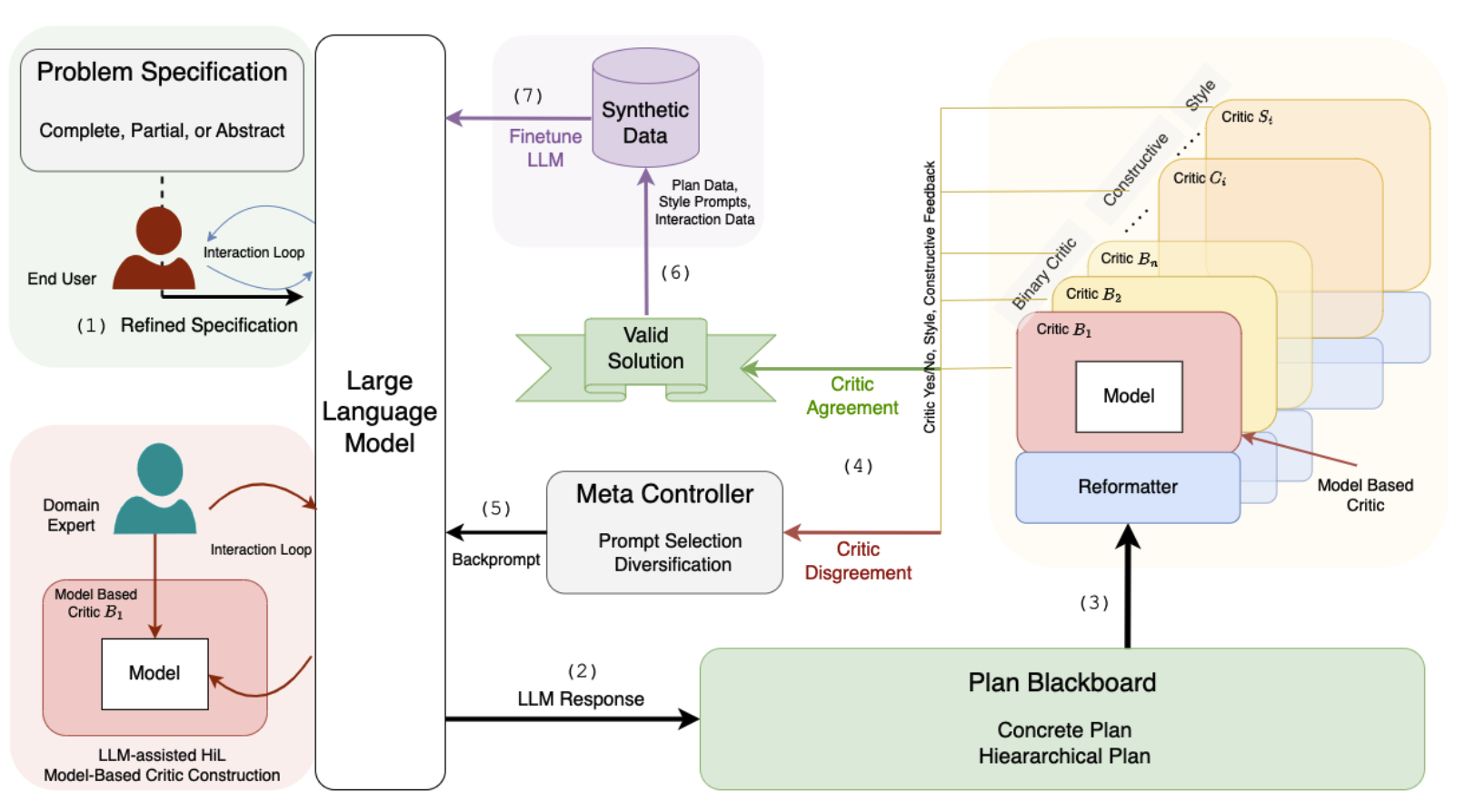 |
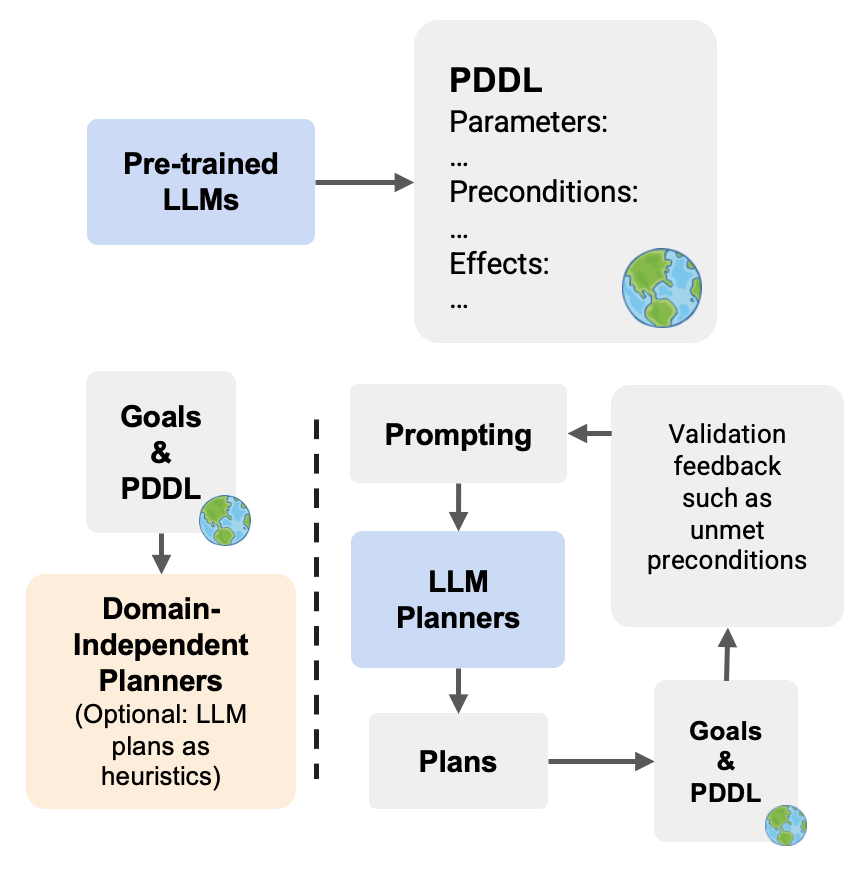
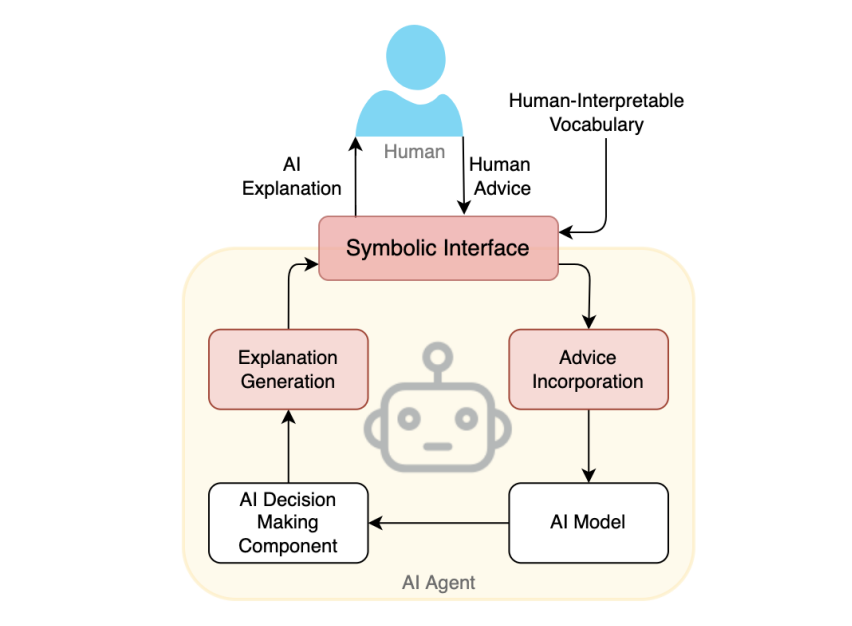
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Kaya Stechly, Mudit Verma, Siddhant Bhambri, Lucas Saldyt, Anil Murthy
ICML 2024, Position Paper
We present the LLM-Modulo Framework in which LLMs play a spectrum of roles, from guessing candidate plans, to translating those plans into syntactic forms that are more accessible to external critics, to helping end users flesh out incomplete specifications, to helping expert users acquire domain models (that in turn drive model-based critics).
paper
|
 |
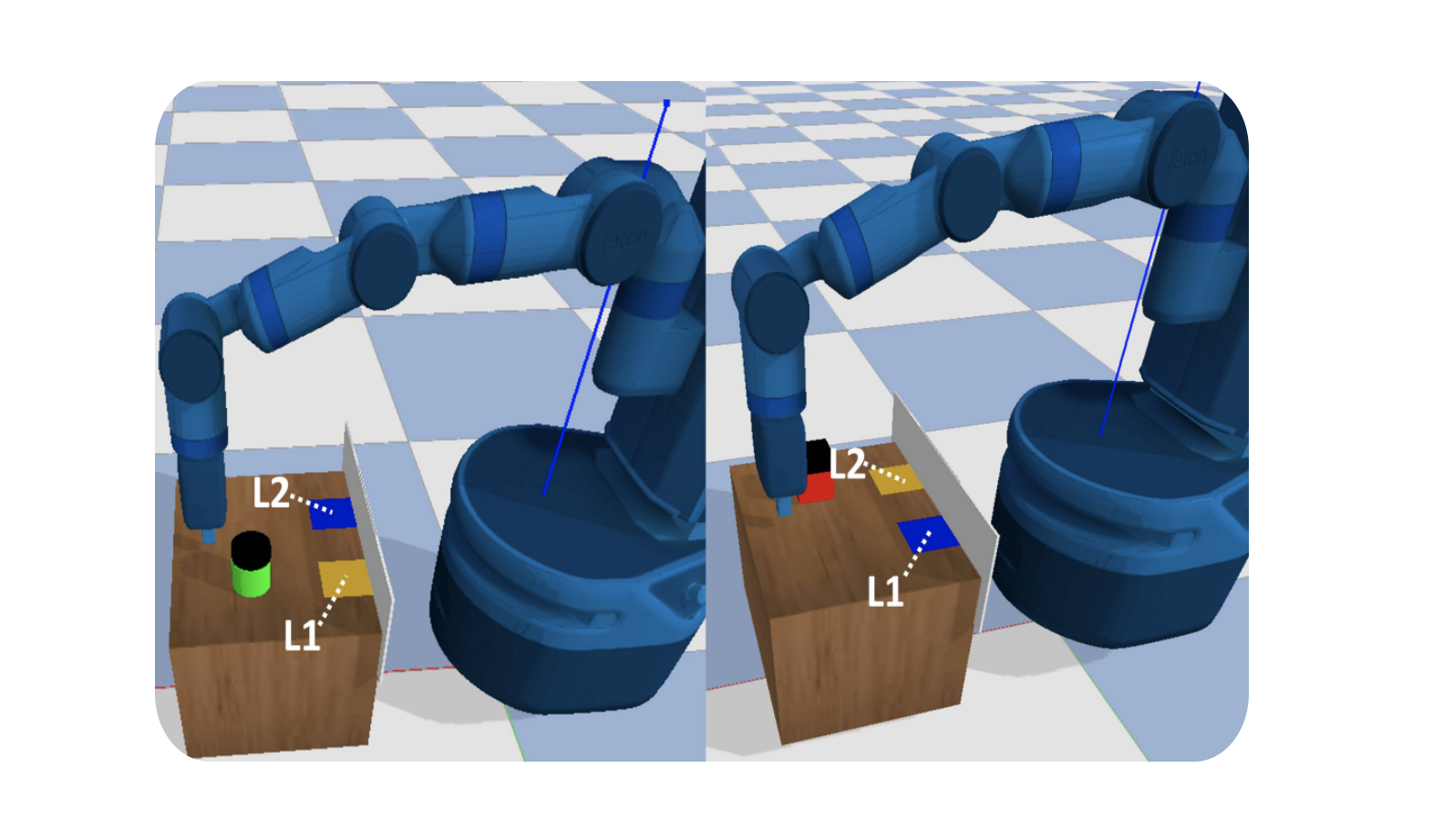
Leveraging Approximate Symbolic Models for Reinforcement Learning via Skill Diversity
Lin Guan*, Sarath Sreedharan* (equal contribution), Subbarao Kambhampati
ICML 2022
(also received the
Best Paper Award
at PRL@ICAPS 2022 and accepted to RLDM 2022)
Explicit symbolic knowledge is important for solving long-horizon task and motion planning tasks.
But a key resistance to leveraging easily available human knowledge (or knowledge acquired from LLMs/VLMs) has been that it might be inexact.
In this work, we present a framework to quantify the relationship between the true task model and an inexact STRIPS model, and
introduce a novel approach using landmarks and a diversity objective to make up for potential errors in the symbolic knowledge.
paper
website
|
 |
On the role of Large Language Models in Planning
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan
Tutorial at AAAI 2024
(also accepted to
ICAPS 2023 Tutorial Program)
This tutorial discusses the fundamental limitations of LLMs in generating plans (especially those that require resolving subgoal interactions), and also presents constructive uses of LLMs for planning tasks.
website
|
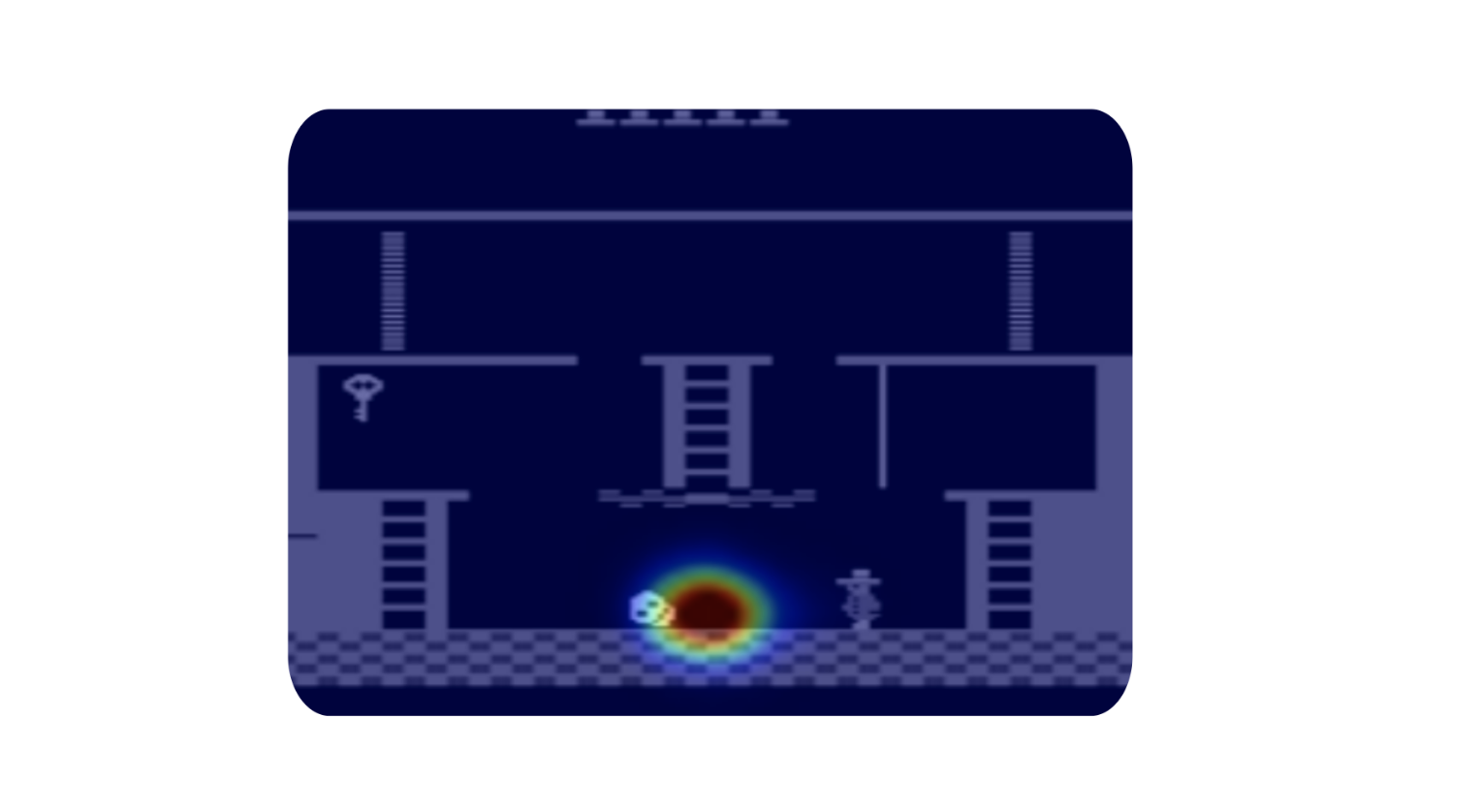 |
Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset
Ruohan Zhang, Calen Walshe, Zhuode Liu, Lin Guan, Karl S. Muller, Jake A. Whritner, Luxin
Zhang, Mary M Hayhoe, Dana H Ballard
AAAI 2020
We provide a large-scale, high-quality dataset of human actions with simultaneously
recorded eye movements (i.e., gaze info) while humans play Atari video games.
paper
|
|