Pick up a bag of chips

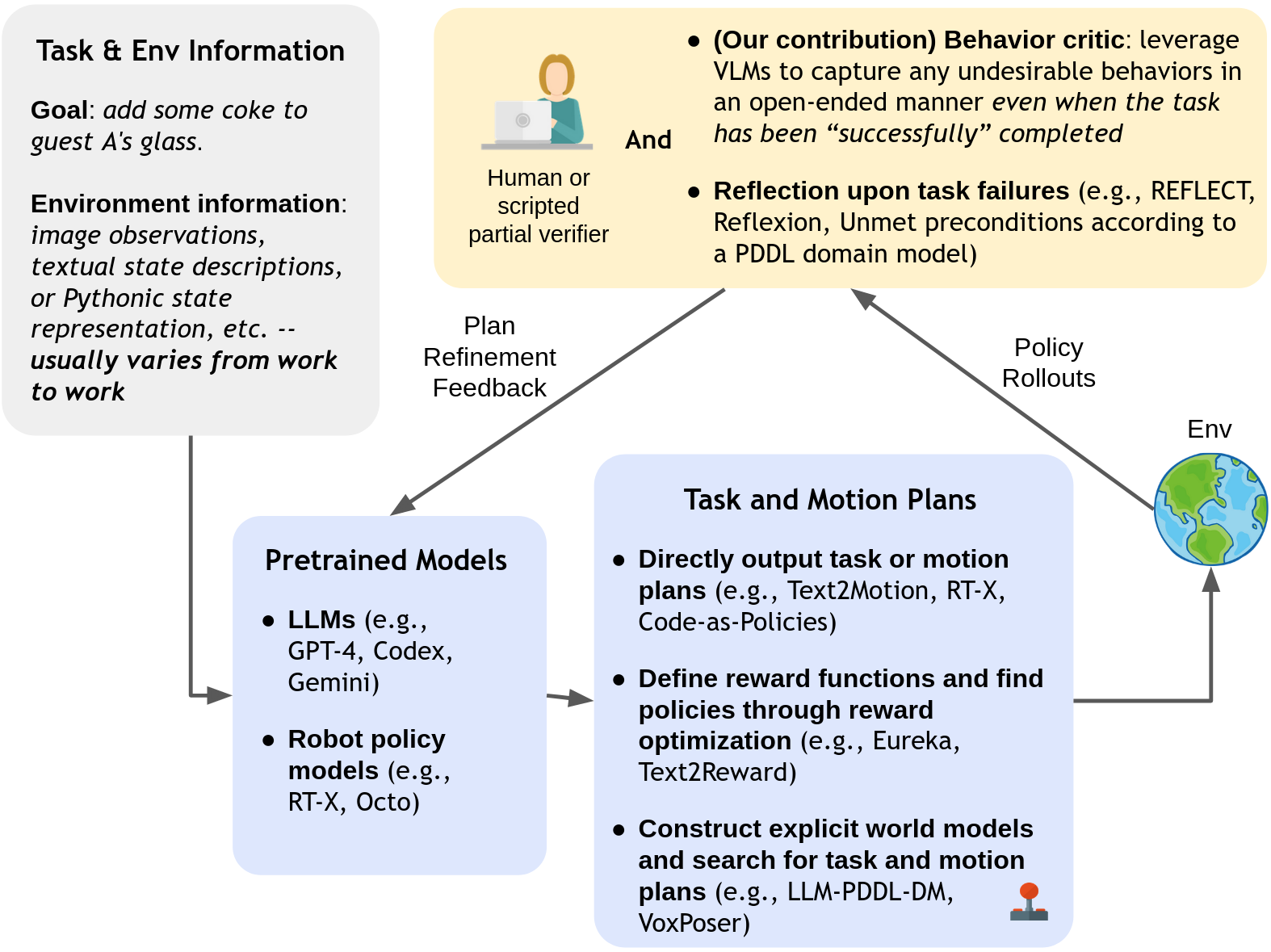
Large-scale generative models are shown to be useful for sampling meaningful candidate solutions, yet they often overlook task constraints and user preferences. Their full power is better harnessed when the models are coupled with external verifiers and the final solutions are derived iteratively or progressively according to the verification feedback. In the context of embodied AI, verification often solely involves assessing whether goal conditions specified in the instructions have been met. Nonetheless, for these agents to be seamlessly integrated into daily life, it is crucial to account for a broader range of constraints and preferences beyond bare task success (e.g., a robot should avoid pointing the blade at a human when handing a knife to the person). However, given the unbounded scope of robot tasks, it is infeasible to construct scripted verifiers akin to those used for explicit-knowledge tasks like the game of Go and theorem proving. This begs the question: when no sound verifier is available, can we use large vision and language models (VLMs), which are approximately omniscient, as scalable Behavior Critics to catch undesirable robot behaviors in videos? To answer this, we first construct a benchmark that contains diverse cases of goal-reaching yet undesirable robot policies. Then, we comprehensively evaluate VLM critics to gain a deeper understanding of their strengths and failure modes. Based on the evaluation, we provide guidelines on how to effectively utilize VLM critiques and showcase a practical way to integrate the feedback into an iterative process of policy refinement.
As the core contribution of this paper, we construct a benchmark which consists of diverse video clips demonstrating suboptimal yet goal-reaching policies in various household tasks.
Pick up a bag of chips

Pour coke into the glass


Move carrot to the plate


Hand scissors to human


Pick up red screwdriver


Place knife on board


Serve orange juice


Open cabinet door


Place facial cleanser


Place vessel onto burner


Move spoon to bowl


Take scissors out of container


We introduce a set of metrics and a taxonomy for characterizing the strengths and failure modes of VLM critics. Detailed explanation can be found in the paper. Here are some key observations:
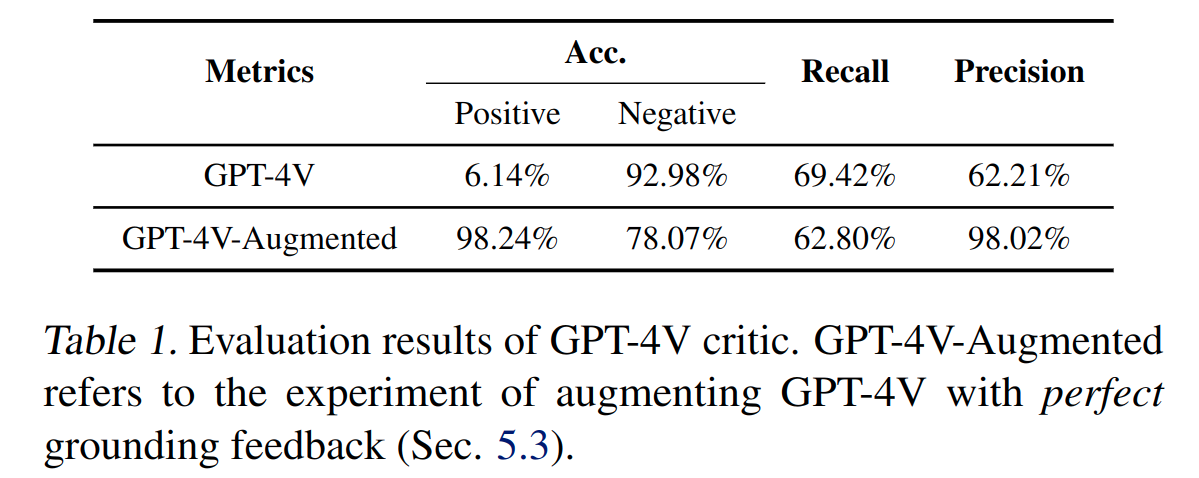
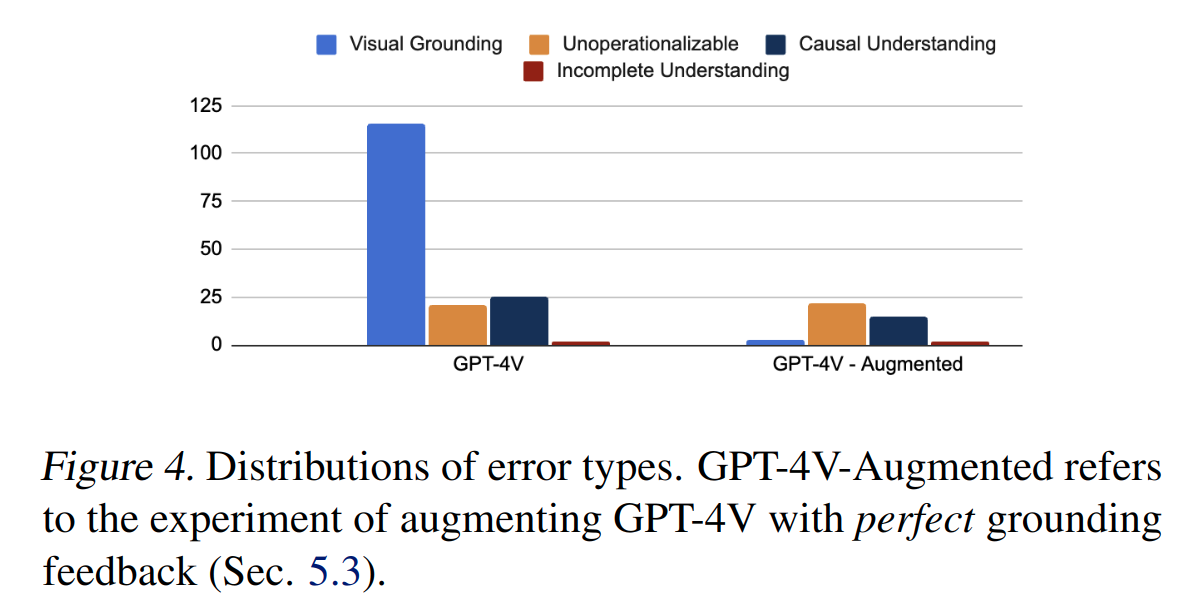
While this work does not take a strong stance on how the critiques should be integrated into closed-loop policy-generation systems, we do present a candidate framework using a real robot in five household scenarios, wherein a Code-as-Policies (CaP) agent iteratively refines the policy according to VLM critiques on the rollouts. We consider 5 tasks within table-top setups: (a) scissor handover; (b) lifting an opened bag; (c) bread grasping; (d) knife placing; and (e) spoon picking. The CaP agent manages to eliminate undesirable behaviors according to VLM critiques in 4 of the tasks.