ICML 2022
Lin Guan*, Sarath Sreedharan*, Subbarao Kambhampati
School of Computing & AI, Arizona State University
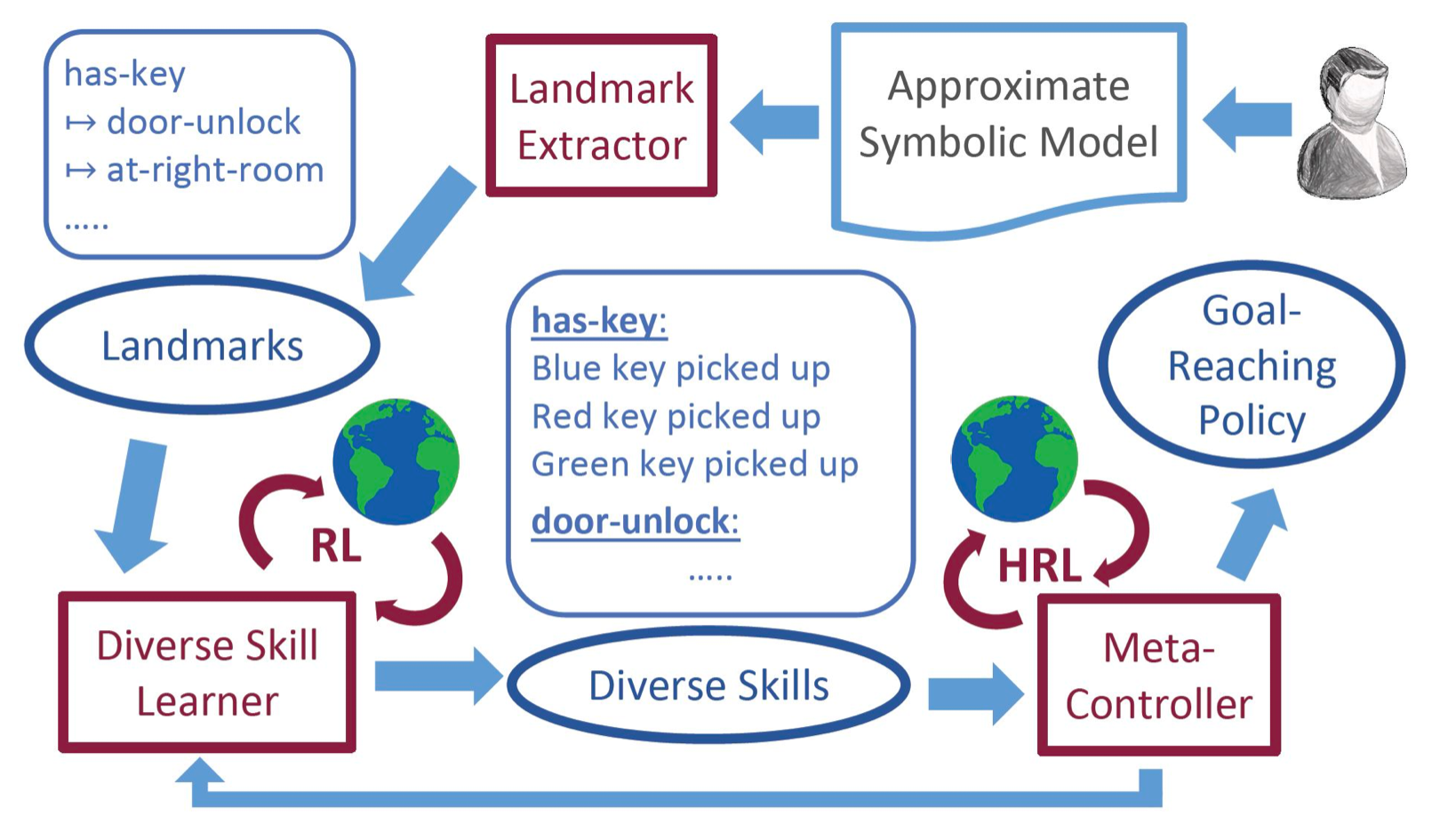
Creating reinforcement learning (RL) agents that are capable of accepting and leveraging task-specific knowledge from humans has been long identified as a possible strategy for developing scalable approaches for solving long-horizon problems. While previous works have looked at the possibility of using symbolic models along with RL approaches, they tend to assume that the high-level action models are executable at low level and the fluents can exclusively characterize all desirable MDP states. Symbolic models of real world tasks are however often incomplete. To this end, we introduce Approximate Symbolic-Model Guided Reinforcement Learning, wherein we will formalize the relationship between the symbolic model and the underlying MDP that will allow us to characterize the incompleteness of the symbolic model. We will use these models to extract high-level landmarks that will be used to decompose the task. At the low level, we learn a set of diverse policies for each possible task subgoal identified by the landmark, which are then stitched together. We evaluate our system by testing on three different benchmark domains and show how even with incomplete symbolic model information, our approach is able to discover the task structure and efficiently guide the RL agent towards the goal.
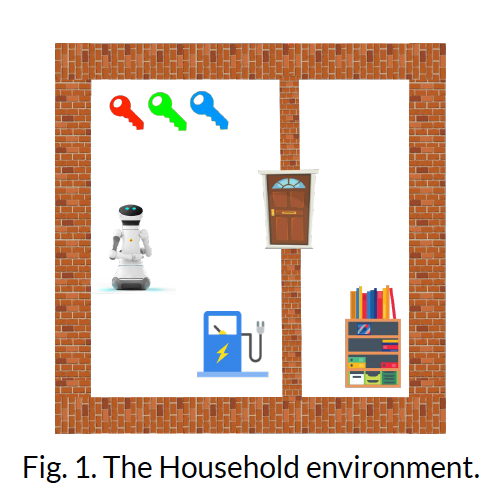
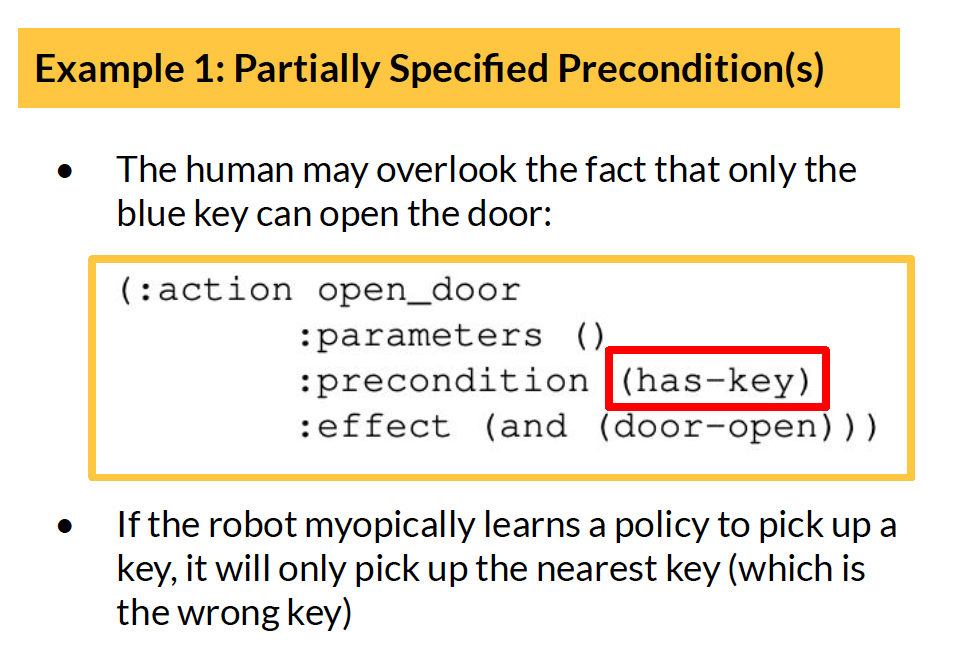
Prior attempts to integrate symbolic planning and reinforcement learning are mainly motivated by the facts that (a) symbolic knowledge/advice can guide RL in challenging long-horizon tasks and improve sample efficiency; (b) symbolic planning methods provide a natural interface for humans to specify goals & constraints (i.e. to define task rewards). Most existing frameworks assume the symbolic models are correct and complete & learn temporally extended operators (options) for symbolic actions. But we can’t guarantee this in practice. Here we give some examples of incomplete & inaccurate models in the Household environment (the task of the robot is to pick up an object on the shelf in the right room):